 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Transfer Limits of Vision Foundation Models
Jan 22, 2026Foundation models leverage large-scale pretraining to capture extensive knowledge, demonstrating generalization in a wide range of language tasks. By comparison, vision foundation models (VFMs) often exhibit uneven improvements across downstream tasks, despite substantial computational investment. We postulate that this limitation arises from a mismatch between pretraining objectives and the demands of downstream vision-and-imaging tasks. Pretraining strategies like masked image reconstruction or contrastive learning shape representations for tasks such as recovery of generic visual patterns or global semantic structures, which may not align with the task-specific requirements of downstream applications including segmentation, classification, or image synthesis. To investigate this in a concrete real-world clinical area, we assess two VFMs, a reconstruction-focused MAE-based model (ProFound) and a contrastive-learning-based model (ProViCNet), on five prostate multiparametric MR imaging tasks, examining how such task alignment influences transfer performance, i.e., from pretraining to fine-tuning. Our findings indicate that better alignment between pretraining and downstream tasks, measured by simple divergence metrics such as maximum-mean-discrepancy (MMD) between the same features before and after fine-tuning, correlates with greater performance improvements and faster convergence, emphasizing the importance of designing and analyzing pretraining objectives with downstream applicability in mind.
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022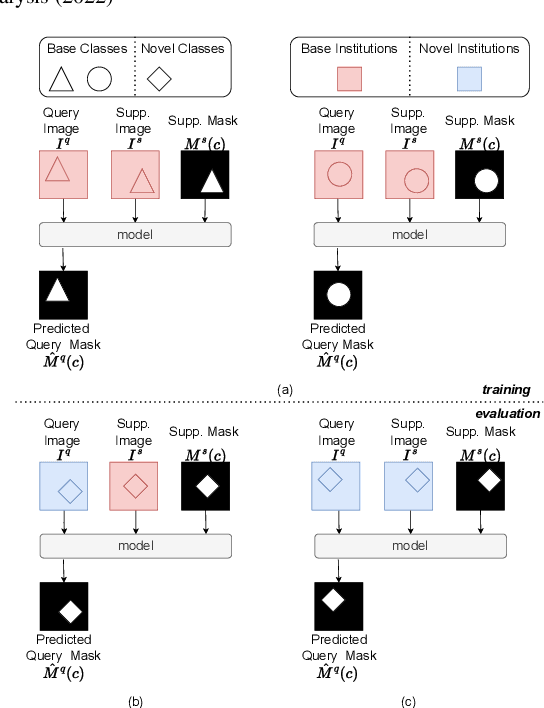

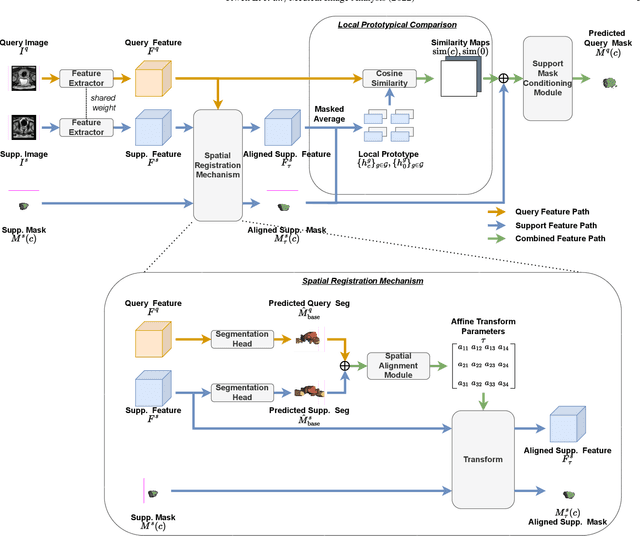

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.